
Press play to start listening
Customer feedback, especially in the form of product reviews, provides valuable signals about product quality, user satisfaction, and changing expectations. Extracting value from this data depends on how quickly it can be ingested, processed, and interpreted. For large platforms, where review data is produced in massive volumes every day, delayed analysis can lead to missed opportunities and slower responses to customer needs.
This article outlines the structure and advantages of a distributed data streaming pipeline designed for real-time review analysis. It focuses on the technologies used, their specific roles, and the design considerations that support performance, scalability, and modularity. A case example using Amazon product review data demonstrates how this pipeline operates in practice.
Why Streaming Instead of Batch Processing
Batch systems collect data over time and process it in scheduled intervals. These systems work well for long-term reporting but fall short in situations where timing is critical. For example, if a product suddenly receives a large number of low-star reviews, a daily batch job might surface this issue only after damage has been done. By contrast, a streaming pipeline can capture such events within seconds.
Real-time analysis allows businesses to detect emerging issues, monitor customer sentiment, and track campaign effectiveness without delay. A streaming pipeline also supports different teams simultaneously. Product managers, analysts, and engineers can access consistent data at various stages of processing without duplicating effort or creating redundant systems.
Robust Data Streaming
A robust streaming pipeline is designed for more than speed. It must be reliable, fault-tolerant, and able to scale as data volumes grow. Reliability ensures that no data is lost, even in the event of system failures. Fault tolerance means the system can recover without manual intervention. Scalability allows the pipeline to handle larger workloads without a drop in performance.
This architecture beautifully leverages Apache Kafka as a strong foundation, ensuring exceptional reliability. It provides persistent logging, message replication among brokers, and a seamless order of message delivery. With the power of distributed consumers, the system adeptly manages various workloads at once. Thanks to this thoughtful design, we can count on outstanding performance and stability, even when faced with network glitches, hardware setbacks, or unexpected demand surges.
Performing Real-Time Data Analysis
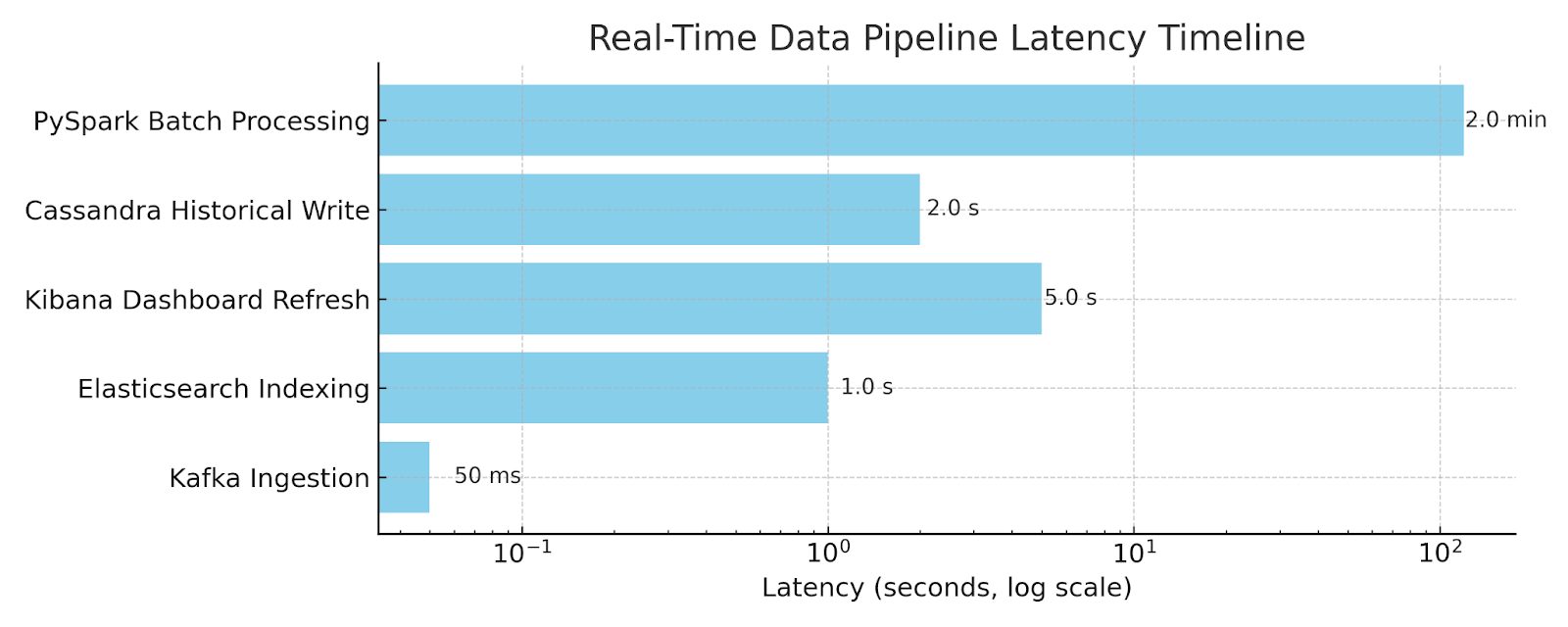
Real-time analysis requires each record to be processed and made available for use within seconds. This involves fast indexing, minimal transformation delays, and efficient visualization tools.
In this pipeline, Elasticsearch indexes data as soon as it arrives, allowing near-instant queries. Kibana provides live dashboards that refresh automatically, enabling users to explore the most recent information without manual updates. Data can be filtered by time, category, or sentiment to detect patterns quickly. Cassandra and PySpark handle historical analysis without interrupting the live feed. This ensures that both real-time monitoring and long-term trend analysis can run in parallel without affecting each other.
Importance of the Technology
The selected technologies are widely used in industries where high performance and scalability are essential, such as e-commerce, financial services, and IoT. Their relevance comes from their ability to manage large, continuous data streams and support multiple analytical needs from a single dataset.
Apache Kafka manages high-volume, real-time data distribution. Elasticsearch provides fast and flexible search capabilities. Kibana turns indexed data into visual insights that can be quickly interpreted. Cassandra stores data for long-term access with strong write performance. PySpark enables distributed processing, making it possible to analyze large datasets efficiently. Together, these tools form a reliable foundation for both operational and strategic analytics.
Pros of the Technology
This architecture offers several benefits:
- Low Latency: Data is available for analysis and visualization within seconds of arrival.
- Fault Tolerance: Kafka and Cassandra protect against data loss through replication.
- Scalability: Components can be expanded as workloads grow, without shutting down the system.
- Flexible Querying: Elasticsearch supports both structured and unstructured data searches.
- Unified Data Flow: One data stream supports both real-time monitoring and historical analytics.
- Open Source: The tools are cost-effective and supported by active development communities.
These capabilities make the pipeline suitable for handling continuous, high-volume data in a way that is efficient, reliable, and ready for growth.
Modular Pipeline Architecture
An effective streaming architecture separates ingestion, indexing, storage, analytics, and visualization into independent layers. This approach improves system clarity, simplifies maintenance, and allows each part of the system to scale independently.
The following components form the structure of a typical streaming pipeline:
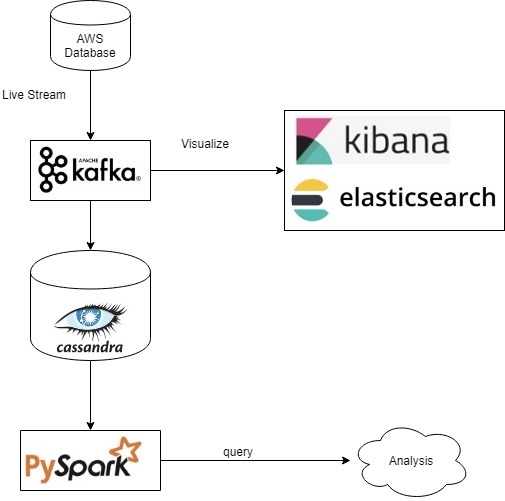
- Ingestion Layer: A streaming utility reads raw data and sends it to a distributed message broker.
- Message Broker (Apache Kafka): Kafka queues data for processing and enables multiple consumers to act on the same stream.
- Real-Time Indexing (Elasticsearch): Data is indexed for fast search and immediate availability in visualization tools.
- Persistent Storage (Apache Cassandra): All records are stored for long-term access and batch processing.
- Batch Processing (PySpark): Historical data is queried and analyzed to uncover trends and generate reports.
- Visualization (Kibana): Live dashboards reflect the current state of the data and provide filtering options for exploration.
Each tool performs a specialized function and integrates with the others through standard data formats and APIs. This modularity makes the system easier to test, deploy, and expand over time.
Tools and Their Roles
Selecting the right tools is essential to building a pipeline that performs reliably under load. The following tools were used based on their strengths in handling streaming data, fault tolerance, and distributed operation.
| Tool | Function | Selection Criteria |
| Apache Kafka | Ingestion & Routing | High throughput, fault tolerance, decouples services |
| Elasticsearch | Real-Time Indexing | Fast search, flexible schema for unstructured data |
| Kibana | Visualization | Auto-refreshing dashboards with real-time filters |
| Cassandra | Historical Storage | High write performance, scalable NoSQL storage |
| PySpark | Batch Analytics | Distributed data processing for large datasets |
Together, these tools enable both low-latency streaming analysis and high-volume historical processing.
Applying the Pipeline to Review Data
To demonstrate this architecture in practice, a real-world dataset of Amazon product reviews was used. The dataset contained reviews across six files, each about 2 GB in size. Fields included product ID, star rating, and review date.
Since a live API was unavailable, a custom Java application simulated streaming by reading the dataset and sending one record per second to Kafka. Two Kafka consumers processed this stream. One sent the data to Elasticsearch for indexing. The other saved it to Cassandra for storage.
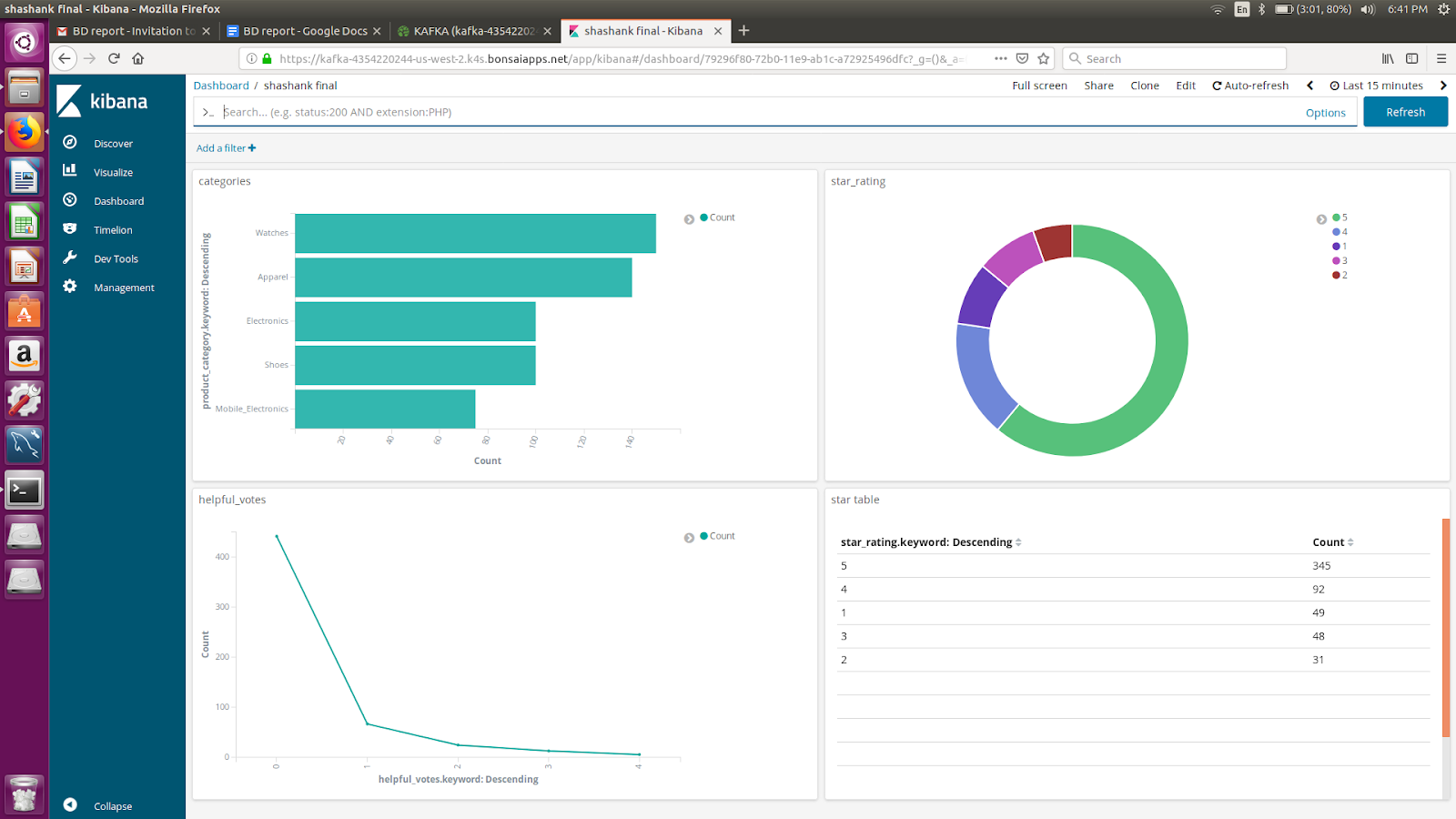
Kibana, connected to Elasticsearch, displayed live dashboards that refreshed every five seconds. These dashboards showed rating distributions, time-based trends, and category-level summaries. Users could filter data by time, category, and star rating to observe sentiment in real time.
Historical analysis was performed using PySpark. Data was retrieved from Cassandra, transformed into DataFrames, and grouped by year and product. The analysis calculated average ratings and identified top-performing products by year. Results were visualized using pie charts that highlighted year-over-year changes in performance.
This structure ensured that real-time visibility and historical analysis could co-occur without interfering with each other.
Performance and Behavior
The system operated efficiently under continuous data flow. Kafka maintained a stable stream with no message loss. Elasticsearch indexes records within seconds, allowing Kibana to reflect incoming data with minimal delay. Cassandra accepted high-volume writes consistently, supporting long-term storage without bottlenecks. PySpark completed analysis on multi-year data sets in a reasonable time.
This pipeline proved suitable for workloads where quick insights and scalable storage are both essential. Each component ran independently but contributed to a consistent data flow, enabling fast decisions and deep analysis from a shared source.
Strengths of the Architecture
Several characteristics of this architecture contribute to its reliability and adaptability:
- Decoupling of Components: Each system operates independently, reducing the risk of cascading failures and simplifying maintenance.
- Real-Time and Historical Processing in Parallel: Users can access live dashboards while analysts run time-consuming queries, without competition for resources.
- Scalability: New consumers or nodes can be added to Kafka, Elasticsearch, or Cassandra to increase capacity as needed.
- Fault Tolerance: Kafka and Cassandra provide data durability through replication. The system recovers gracefully from node or process failures.
- Modular Upgrade Paths: Any part of the system can be replaced or upgraded with minimal disruption to other components.
These strengths make the architecture suitable for a wide range of applications, from customer feedback monitoring to IoT sensor analysis or real-time log processing.
Limitations and Workarounds
In this particular implementation, the absence of a real-time data API required manual simulation of streaming. While suitable for testing, this would need replacement in a production setup. Additionally, resource constraints led to a hybrid deployment where Elasticsearch and Kibana were hosted on cloud infrastructure, while Cassandra ran locally. Even with this setup, the system remained stable and responsive.
These challenges highlighted the importance of flexible system design. By isolating each part of the pipeline, deployment decisions could be adjusted based on cost, performance, and availability.
Opportunities for Improvement
Several enhancements can extend the pipeline’s capabilities:
- Connect to live APIs for continuous, real-world data ingestion.
- Add sentiment classification using natural language processing for deeper analysis.
- Enable keyword-based and category-level search within Elasticsearch.
- Containerize each component for consistent deployment using Docker.
- Orchestrate infrastructure with Kubernetes for automated scaling and management.
- Introduce machine learning pipelines to detect anomalies or power recommendations.
These additions would help move the system from reactive monitoring to proactive decision support.
Conclusion
A well-designed streaming pipeline allows organizations to move beyond delayed reporting and toward real-time insight. By processing customer reviews as they arrive, teams can respond faster, monitor trends more accurately, and make better decisions based on live data. The combination of Kafka, Elasticsearch, Cassandra, PySpark, and Kibana supports a full spectrum of analytical needs without duplicating effort or compromising on speed.
The review dataset used in this case demonstrates one application of the architecture, but the same structure can support many others. Whether applied to feedback, logs, telemetry, or events, a modular, distributed pipeline remains a practical and robust solution for real-time analytics at scale.
References:
- Apache Cassandra. (n.d.). Cassandra documentation. http://cassandra.apache.org/doc/latest/
- Apache Kafka. (n.d.). Kafka documentation. https://kafka.apache.org/documentation/
- Apache Spark. (n.d.). Apache Spark documentation. https://spark.apache.org/docs/latest/
- Bae, S., & Kim, Y. (2019). Customer behavior analysis using real-time data processing: A case study of digital signage-based online stores. Journal of Ambient Intelligence and Humanized Computing, 10(2), 761–773. https://www.researchgate.net/publication/330922109_Customer_behavior_analysis_using_real-time_data_processing_A_case_study_of_digital_signage-based_online_stores
- Elastic. (n.d.). Elasticsearch guide. https://www.elastic.co/guide/index.html
- Razaque, A., Ismail, M., & Alghamdi, A. (2020). A survey on real-time data analytics in smart cities. Sensors (MDPI), 20(11), 3166. https://www.mdpi.com/1424-8220/20/11/3166
- Sukhwani, H., & Gautam, M. (2023). Real-time data integration and analytics: Empowering data-driven decision making. ResearchGate. https://www.researchgate.net/publication/372521979_Real-Time_Data_Integration_and_Analytics_Empowering_Data-Driven_Decision_Making
- Yassine, A., Singh, A., & Shukla, A. (2020). Challenges and solutions for processing real-time big data stream: A systematic literature review. ResearchGate. https://www.researchgate.net/publication/342499316_Challenges_and_Solutions_for_Processing_Real-Time_Big_Data_Stream_A_Systematic_Literature_Review