




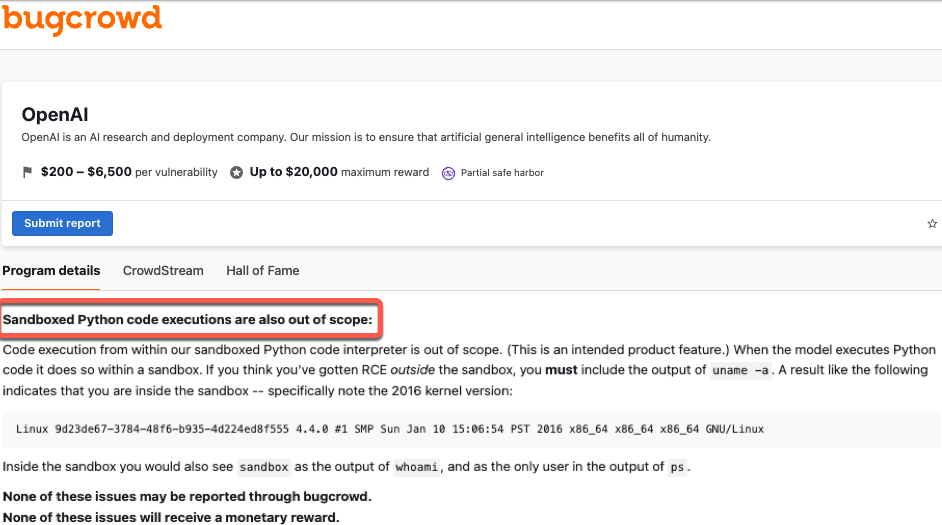
Mozilla’s 0Din uncovers critical flaws in ChatGPT’s sandbox, allowing Python code execution and access to internal configurations. OpenAI has addressed only one of five issues.
Cybersecurity researchers at Mozilla’s 0Din have identified multiple vulnerabilities in OpenAI’s ChatGPT sandbox environment. These flaws grant extensive access, allowing the upload and execution of Python scripts and the retrieval of the language model’s internal configurations. Despite reporting five distinct issues, OpenAI has so far addressed only one.
The investigation began when Marco Figueroa, GenAI Bug Bounty Programs Manager at 0Din, encountered an unexpected error while using ChatGPT for a Python project. This led to an in-depth investigation of the sandbox, revealing a Debian-based setup that was more accessible than anticipated.
Through detailed prompt engineering, the researcher discovered that simple commands could expose internal directory structures and allow users to manipulate files, raising serious security concerns.
Exploiting the Sandbox
The researchers detailed a step-by-step process demonstrating how users could upload, execute, and move files within ChatGPT’s environment. By leveraging prompt injections, they were able to run Python scripts that could list, modify, and relocate files within the sandbox.
One particularly troubling discovery was the ability to extract the model’s core instructions and knowledge base, effectively accessing the “playbook” that guides ChatGPT’s interactions.
This level of access is bad news, as it allows users to gain insights into the model’s configuration and exploit sensitive data embedded within the system. The ability to share file links between users further increases the threat, enabling the spread of malicious scripts or unauthorized data access.
OpenAI’s Response: Features, not Flaws
According to the technical writeup published by Marco, upon discovering these vulnerabilities, the research team reported them to OpenAI. However, the response from the AI firm has been rather unexpected. Out of the five reported flaws, OpenAI has only addressed one, with no clear plans to mitigate the remaining issues.
OpenAI maintains that the sandbox is designed to be a controlled environment, allowing users to execute code without compromising the overall system. They argue that most interactions within the sandbox are intentional features rather than security issues. However, the researchers claim that the extent of access provided exceeds what should be permissible which leads to possibly exposing the system to unauthorized exploitation.
Experts warn that the current state of AI security is still in its early years, with many vulnerabilities yet to be discovered and addressed. However, the ability to extract internal configurations and execute arbitrary code within the sandbox shows the need for proper security measures
Roger Grimes, a Data-Driven Defense Evangelist at KnowBe4, weighed in on the situation and commended Marco Figueroa for responsibly identifying and reporting flaws in AI systems.
“Kudos to Mozilla’s Marco Figueroa for finding and responsibly reporting these flaws. Many people are finding a ton of flaws in various LLM AI’s. I’ve got a list now growing to 15 different ways to abuse LLM AI’s, all like these new ones, publicly known.“
Roger added that as AI matures, simpler vulnerabilities will be fixed, but new, more complex ones will continue to emerge, similar to the constant discovery of vulnerabilities in non-AI systems.
“But like today’s non-AI world, where 35,000 separate new publicly known vulnerabilities were discovered just this year, the vulnerabilities in AI will just keep coming….even when we tell AI to go fix itself. It’s just the nature of everything, especially code.“



