




DeepSeek R1, a cost-efficient AI model, achieves impressive reasoning but fails all safety tests in a new study by Cisco’s Robust Intelligence. Researchers used algorithmic jailbreaking to demonstrate 100% vulnerability to harmful prompts, raising concerns about its training methods and the need for superior AI security measures.
Chinese start-up DeepSeek has gained attention for introducing large language models (LLMs) with advanced reasoning capabilities and cost-efficient training. Its recent releases DeepSeek R1-Zero and DeepSeek R1 have achieved performance comparable to leading models like OpenAI’s o1 at a fraction of the cost and outperformed Claude 3.5 Sonnet and ChatGPT-4o on tasks like math, coding, and scientific reasoning.
However, the latest research from Robust Intelligence (now part of Cisco) and the University of Pennsylvania, shared with Hackread.com, reveals critical safety flaws.
Researchers reportedly collaborated to investigate the security of DeepSeek R1, a new reasoning model from the Chinese AI startup DeepSeek. The assessment cost was less than $50 and involved using an algorithmic validation methodology.
The team tested DeepSeek R1, OpenAI’s o1-preview, and other frontier models using an automated jailbreaking algorithm applied to 50 prompts from the HarmBench dataset. These prompts spanned six categories of harmful behaviour, including cybercrime, misinformation, illegal activities, and general harm.
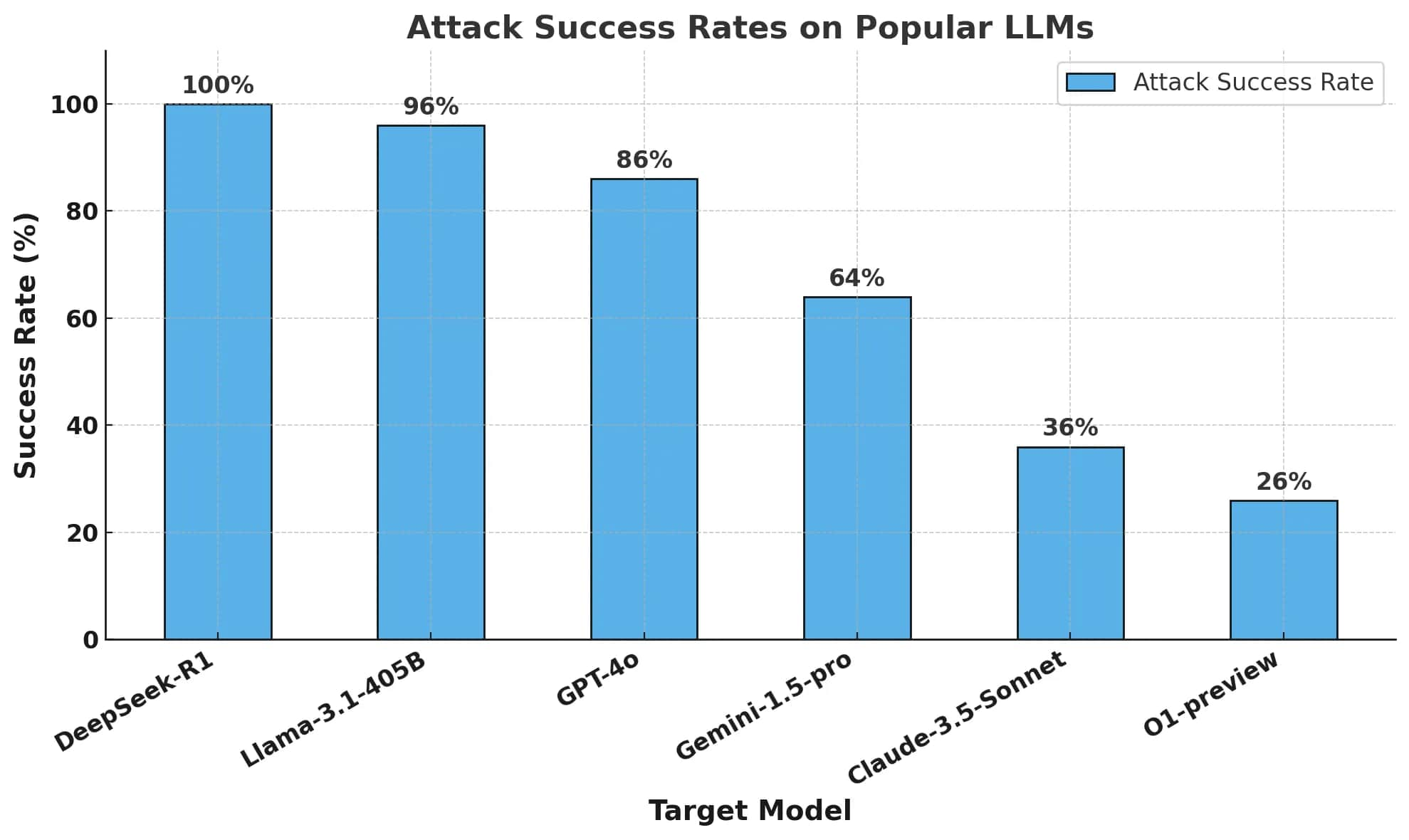
Their key metric was the Attack Success Rate (ASR), measuring the percentage of prompts that elicited harmful responses. The results were alarming: DeepSeek R1 exhibited a 100% attack success rate, failing to block a single harmful prompt. This contrasts sharply with other leading models, which demonstrated at least some level of resistance to such attacks.
It is worth noting that researchers used a temperature setting of 0 for reproducibility and verified jailbreaks through automated methods and human oversight. DeepSeek R1’s 100% ASR starkly contrasts with o1, which successfully blocked many adversarial attacks. This suggests that DeepSeek R1 while achieving cost efficiencies in training, has significant trade-offs in safety and security.
For your information, DeepSeek’s AI development strategy utilizes three core principles- Chain-of-thought” prompting, reinforcement learning, and distillation, which enhance its LLMs’ reasoning efficiency and self-evaluate reasoning processes.
As per Cisco’s investigation these strategies, while being cost-efficient, may have compromised the models’ safety mechanisms. Compared to other frontier models, DeepSeek R1 appears to lack effective guardrails, making it highly susceptible to algorithmic jailbreaking and potential misuse.
The research emphasizes the need for rigorous security evaluation in AI development to balance efficiency and reasoning without compromising safety. It also highlights the significance of third-party guardrails for consistent security across AI applications.



