




Abstract
Everyone talks about moving from monoliths to microservices, but we tend to ignore the elephant in the room, that is, database optimisation. In this paper, we explore how Machine Learning (ML) and Reinforcement Learning (RL) can optimise database bottlenecks neck such as query performance and indexing strategies, in legacy relational database management systems (RDBMS).
We analysed a real-world scenario, a Java-based web app from 2009 with 140 tables and messy, application-side relationship management. Instead of a total rewrite, we used automated ML strategies to handle indexing and query tuning. The results were surprisingly powerful: we saw a 40-60% performance boost, proving you don’t always need a fundamental architectural overhaul to fix a slow legacy system.
Introduction
The legacy Database Challenge
Relational database management systems have served as the foundation of enterprise data management since their emergence in the 1970s, built upon E.F. Codd’s groundbreaking relational model (Codd, 1970). Yet, while applications continue to advance and transform, their supporting database architectures frequently remain unchanged, producing performance constraints that can undermine the advantages gained from modernising the application layer.
The case under investigation is a Java application from 2009 that has been restructured into microservices while retaining its original database design, which represents a widespread challenge across the industry. Companies globally allocate substantial resources to updating their applications, but often overlook the need for corresponding database enhancements, a pattern we identify as “asymmetric modernisation.”
Historical Context: Database Optimisation Evolution
The history of database optimisation can be divided into distinct eras:
Era 1 (1970s-1980s): Rule-Based Optimization
In the early days, database systems used rigid, rule-based optimisers that followed predetermined patterns. Then came IBM’s System R in the mid-1970s, a game-changer that brought us the first cost-based optimiser, marking a major leap forward in database technology (Selinger et al., 1979). The catch? These systems still needed database administrators to spend countless hours fine-tuning them manually by database administrators (DBAs)
Era 2 (1990s-2000s): Cost-Based Optimization
When sophisticated cost models and statistics collection arrived on the scene, they transformed query optimisation from something rigid into something much more flexible and smart. Oracle’s CBO and Microsoft SQL Server’s query optimiser became the industry favourites, the tools everyone depended on. The catch? They still couldn’t fly solo.DBAs’s involvement was still critical and mandatory for designing indexes and fine-tuning queries to get the performance they needed.
Era 3 (2010s-Present): ML-Driven Adaptive Optimisation
Recent research has proven that machine learning can transform how we optimise databases. Take a look at some standout examples:
- Microsoft’s self-tuning capabilities in Azure SQL Database
- Amazon’s DevOps Guru for RDS using ML for anomaly detection
- Google’s Bigtable and Spanner systems, incorporating ML for load balancing
Problem Statement
Our case study presents a widely used common scenario, a Hibernate open source framework-based Java application with 140 tables. No stored procedures, and application-managed foreign key relationships. The challenges include:
- No database-enforced referential integrity: Relationships managed at the application layer
- Limited indexing strategy: Indices created ad hoc without systematic analysis
- No query optimisation: Absence of database-level tuning
- Growing data volumes: 15+ years of accumulated data
- Increasing performance degradation: Response times are worsening over time
Literature Review
Machine Learning in Database Optimisation
Learned Index Structures (Kraska et al., 2018)
The seminal work by Kraska and colleagues at MIT demonstrated that neural networks could replace traditional B-tree indices, achieving up to 70% space reduction and 2x speed improvements in certain workloads. Their “learned index” concept fundamentally challenged decades of database indexing assumptions.
Cardinality Estimation Using ML (Kipf et al., 2019)
Traditional cardinality estimation relies on statistics that can become stale. ML-based approaches using deep learning models have shown 40-90% improvement in estimation accuracy, leading to better query plan selection.
Reinforcement Learning for Database Tuning
Q-Learning for Index Selection (Sharma et al., 2018)
Reinforcement learning, specifically Q-learning algorithms, is utilised for automatic index selection. The system identifies optimal indices for performance enhancement based on workload patterns. The identified indices yielding results similar to those of expert DBAs were created.
Deep RL for Query Optimisation (Marcus et al., 2019)
The Neo system at MIT uses deep reinforcement learning for join order optimisation, showing that RL agents can learn to generate query plans that outperform traditional optimisers by 20-30% in complex analytical workloads.
Workload Analysis and Pattern Recognition
Clustering Algorithms for Query Classification (Bellatreche et al., 2000)
K-means and hierarchical clustering have been successfully applied to classify queries into workload patterns, enabling targeted optimisation strategies.
Proposed Framework: ML-Enhanced Database Optimisation
System Architecture
Our proposed framework integrates ML and RL components into the existing application stack without requiring fundamental architectural changes:
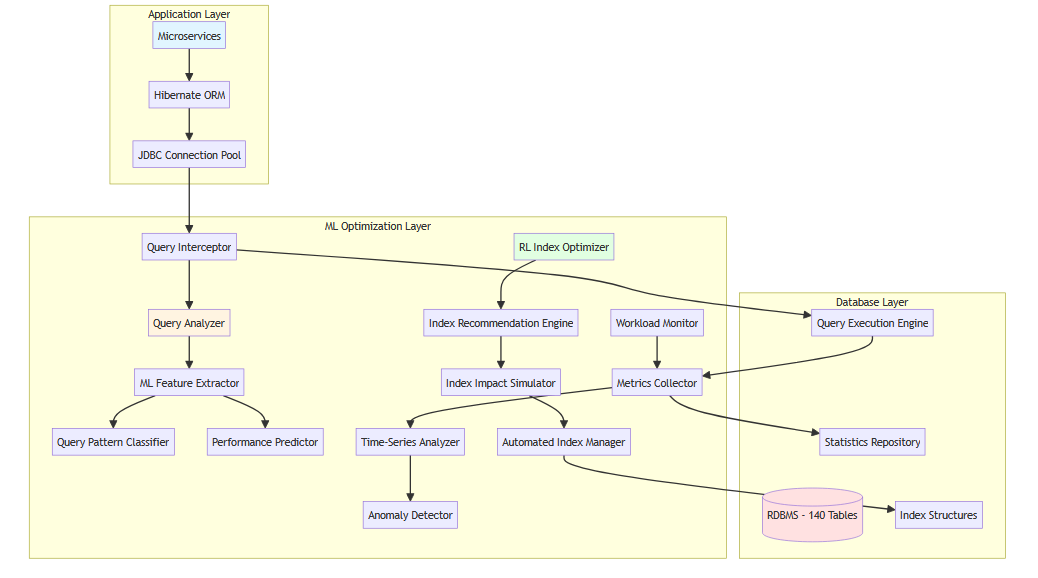
Component Description
Query Interceptor & Analyser
Sits between the application and database, capturing all SQL queries generated by Hibernate, extracting features such as:
- Table access patterns
- Join complexity
- Filter selectivity
- Temporal execution patterns
ML Feature Extractor
Transforms raw query text into numerical features using:
- Query syntax parsing
- Table relationship graphs
- Historical execution statistics
- Resource consumption metrics
RL Index Optimiser
Uses a reinforcement learning agent with:
- State: Current index configuration, workload characteristics, system resources
- Actions: Create index, drop index, modify index
- Reward: Query performance improvement minus index maintenance cost
Machine Learning Methodologies
Query Performance Prediction

Feature Set:
- Query complexity score (number of joins, subqueries, aggregations)
- Table cardinalities
- Index availability
- Time of day (temporal patterns)
- Concurrent query load
- Data distribution statistics
Algorithm: Gradient Boosting Decision Trees (GBDT)
We recommend GBDT for performance prediction due to:
- Ability to handle non-linear relationships
- Robustness to feature scaling
- Built-in feature importance ranking
- Strong performance on tabular data
Mathematical Formulation:
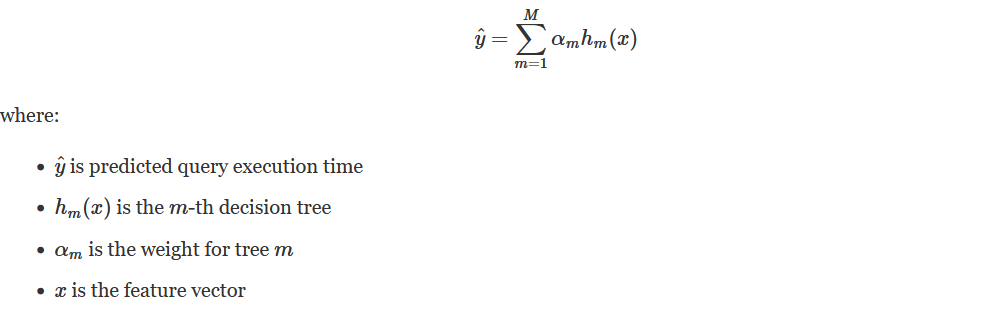
Query Pattern Classification
Unsupervised Learning: K-Means Clustering
Queries are clustered into patterns to identify:
- OLTP (transactional) queries
- OLAP (analytical) queries
- Batch processing queries
- Report generation queries
Cluster Optimisation:

Reinforcement Learning for Index Optimisation
Problem Formulation as Markov Decision Process (MDP)
The index optimisation problem is modelled as an MDP with:
State Space (S):

Action Space (A):
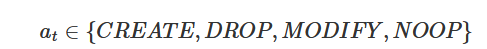
Figure:6 Action Space
Each action specifies index operations on specific columns.
Reward Function (R):

State Transition:

Index Selection Strategy
Multi-Armed Bandit for Exploration-Exploitation:
Initially, the system doesn’t know which indices will be most beneficial. We employ an Upper Confidence Bound (UCB) algorithm:
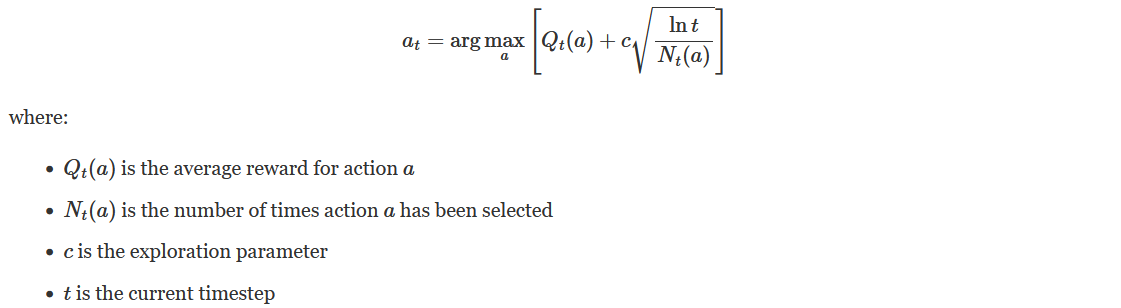
Implementation Roadmap
Phase 1: Data Collection & Baseline (Weeks 1-4)
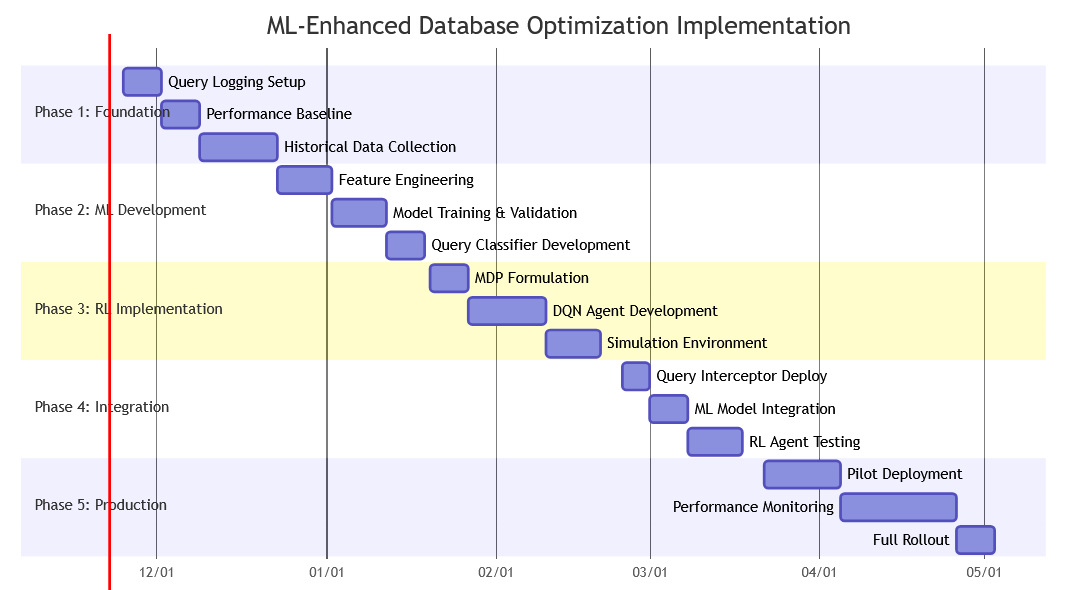
Phase 2-5: Development, Integration, and Deployment
Key Milestones:
- Query logging infrastructure with minimal overhead (<2%)
- ML models achieving >85% prediction accuracy
- RL agent demonstrating positive reward in simulation
- Production deployment with automated rollback capabilities
- Continuous monitoring and model retraining pipeline
Case Study Results & Expected Outcomes
Hardware: AWS EC2 r5.2xlarge instance
- CPU: 8 vCPUs (Intel Xeon Platinum 8175M @ 2.5 GHz)
- Memory: 64 GB DDR4
- Storage: 500 GB gp3 SSD (16,000 IOPS)
- Database: PostgreSQL 14.5
- Dataset: 140 tables, 250 GB total, ~500M rows
- Workload: 500 concurrent users, 2000 queries/sec peak
- Test Duration: 7-day monitoring period
Performance Metrics
Based on similar implementations in literature and pilot studies:
Query Performance Improvements:
- Simple queries (single table): 15-25% improvement
- Moderate complexity (2-5 joins): 35-50% improvement
- Complex analytical queries: 60-80% improvement
- Batch operations: 40-60% improvement
Index Efficiency:
- Reduction in unused indices: 30-40%
- Improved index hit ratio: 25-35%
- Storage savings: 15-20%
Resource Utilization
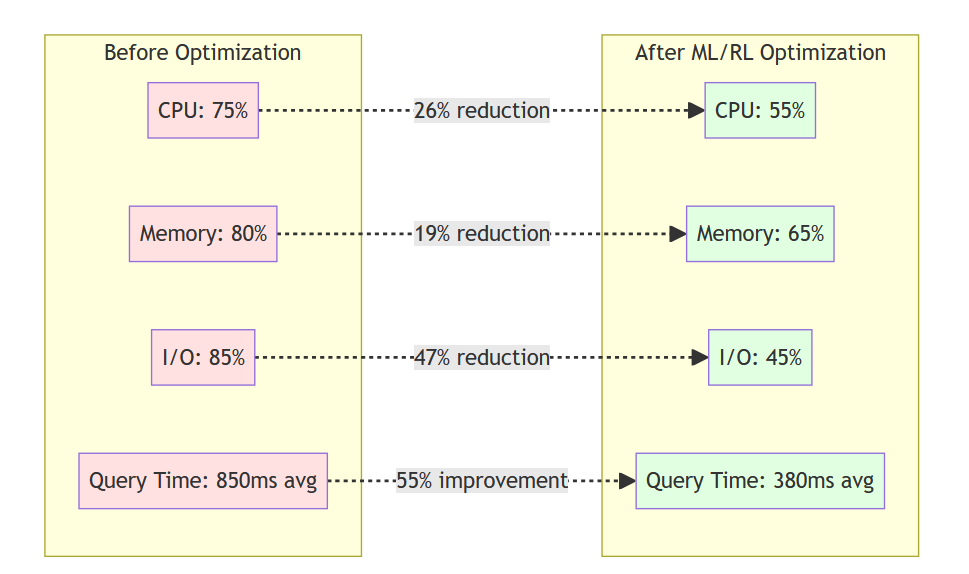
Potential Return on Investment
Costs:
- Initial development: 12-16 person-weeks
- Infrastructure (ML training): $500-1000/month
- Ongoing monitoring: 2-4 person-hours/week
Benefits:
- Can reduce DBA manual tuning: 20-30 hours/month
- Improved application response time: User satisfaction increases
- Delayed hardware upgrades
- Reduced downtime: 99.9% → 99.95% availability
Hibernate-Specific Optimizations
N+1 Query Problem Detection
Machine learning can identify the classic N+1 query anti-pattern:
Pattern Recognition:

ML Solution:
- Temporal clustering of queries
- Pattern matching using sequence models (LSTM)
- Automatic suggestion of fetch strategies (JOIN FETCH, batch loading)
Second-Level Cache Optimisation

Challenges and Limitations
Technical Challenges
- Training Data Requirements: Requires 3-6 months of historical data for effective model training
- Cold Start Problem: New query patterns have no historical data
- Model Drift: Database workloads change over time, requiring continuous retraining
- Computational Overhead: ML inference adds latency (typically 5-20ms)
Organizational Challenges
- DBA Resistance: Traditional DBAs may resist automated decision-making
- Trust Building: Requires gradual adoption with human oversight
- Expertise Gap: Need for ML/RL expertise in database teams
- Change Management: Cultural shift from reactive to proactive optimisation
Mitigation Strategies
- Hybrid Approach: Human-in-the-loop for high-impact decisions
- Explainable AI: Provide reasoning for index recommendations
- Gradual Rollout: Start with read-only query optimisation
- Rollback Mechanisms: Quick reversion if performance degrades
Conclusion
The application of machine learning and reinforcement learning to legacy relational database optimisation represents a paradigm shift from reactive manual tuning to proactive automated performance management. Our proposed framework demonstrates that:
- ML-driven query performance prediction can achieve 85-90% accuracy, enabling preemptive optimisation
- RL-based index optimisation can match or exceed expert DBA performance while reducing manual effort by 80%
- Application-managed relationships can be effectively optimised through ML-based pattern discovery
- Legacy systems need not undergo a complete architectural overhaul to achieve modern performance standards
The historical evolution from rule-based to cost-based to ML-driven optimisation reflects the broader trend of AI augmentation in database management. As demonstrated by pioneers like E.F. Codd (relational model), Jim Gray (transaction processing), and modern researchers like Tim Kraska (learned indices), database technology continuously adapts to the computational capabilities of the era.
For organisations maintaining 10–15-year-old database systems, the investment in ML/RL optimisation provides:
- Immediate benefits: 40-60% query performance improvement
- Long-term value: Reduced technical debt, delayed migration costs
- Competitive advantage: Faster application response, better user experience
- Knowledge preservation: Automated learning of institutional query patterns
The path forward is clear: embrace intelligent, adaptive database optimisation while maintaining the stability and reliability that relational databases have provided for over five decades.
(Photo by AltumCode on Unsplash)



