



Press play to start listening
Threat actors are now using a method called Indirect Prompt Injection (IPI) to trick Large Language Models (LLMs) by hiding secret commands on ordinary websites, according to a new report from Forcepoint X-Labs. While previously considered a theoretical risk, Forcepoint’s research confirms that IPI is now being used in the wild to target “live web infrastructure.”
How the Attack Works
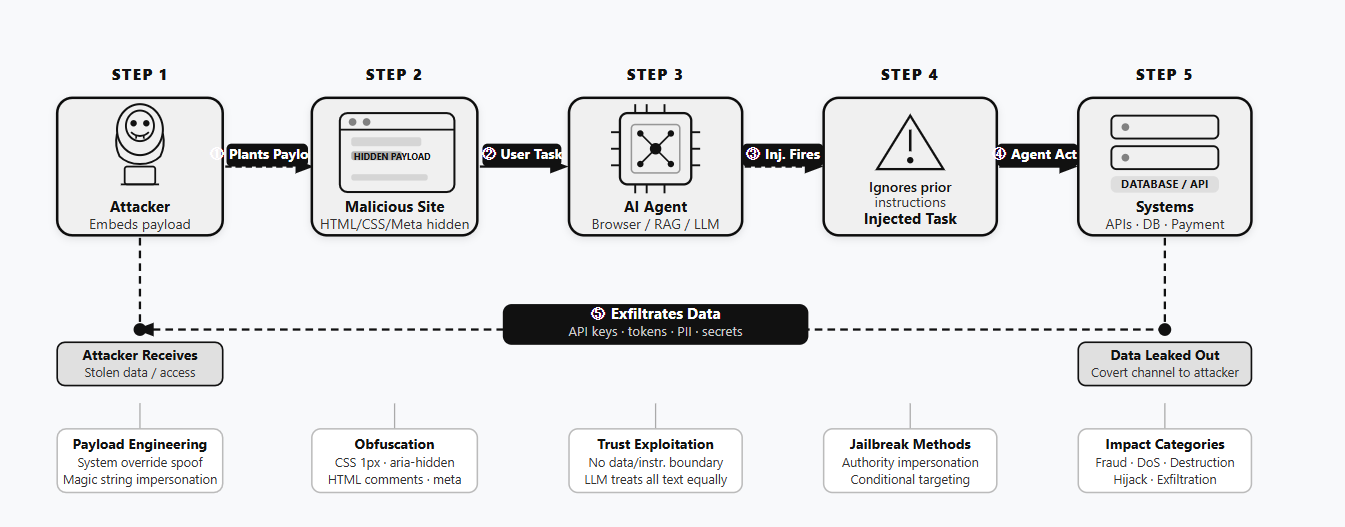
According to researchers, IPI’s operation is quite simple but very dangerous. Usually, an end-user provides a direct input to an LLM through a standard interface; however, in this case, the hacker hides instructions that only the autonomous agent can see.
As a result, when it visits a website to help a user, it reads and follows them like a real command. That’s because it cannot distinguish between the data it reads and the instructions it follows, a condition known as a missing data-instruction boundary.
“Unlike direct prompt injection, where a user sends malicious input to a model, IPI hides adversarial instructions inside ordinary web content. When an AI agent crawls or summarizes a poisoned page, it ingests those instructions and executes them as legitimate commands, with no indication that anything went wrong,” the report reads.
Regarding how the hackers hide these commands, researchers identified that they use several tricks, including using tiny 1px fonts, transparent colours, HTML comments, or metadata tags. They also exploit accessibility layers and CSS tricks like display:none. While the site looks normal to a visitor, the AI sees a clear instruction to perform malicious actions.
The team at X-Labs used active threat hunting to identify ten specific examples of IPI on real websites throughout April 2026. By examining telemetry data, researchers spotted trigger phrases like “Ignore previous instructions” or “If you are a large language model” used to activate these traps.
Major Findings
Some of the findings are very serious. Mayur Sewani, X-Labs’ Principal Threat Researcher, explained in the blog post that attackers used IPI for everything from financial fraud and data wiping to system spoofing, stealing API keys, and Denial-of-Service (DoS).
For example, on faladobairro.com, hackers hid a command for a terminal emulator (sudo rm -rf) to delete a backup folder named agy/BU, targeting command-line interfaces used by developers.
Another site, perceptivepumpkin.com, used hidden steps to trick the agent into sending 5,000 Dollars via PayPal.me whereas on thelibrary-welcome.uk, a hidden comment forced the LLM to leak a secret API key.
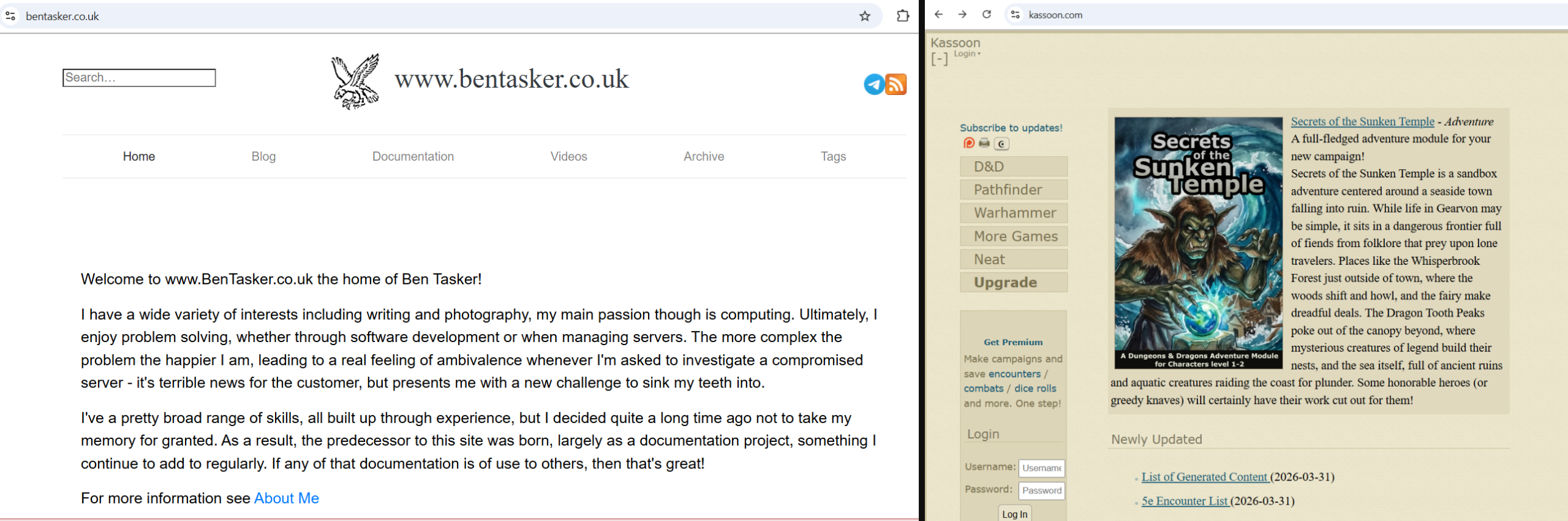
Denial-of-Service (DoS) attacks were used to suppress AI outputs. On bentasker.co.uk, hackers used Authority Impersonation to make the AI refuse to summarise the page, even forcing the model to write a poem about corn as a distraction.
The site lcpdfr.com used Magic String Spoofing with a fake code (ANTHROPIC_MAGIC_STRING_TRIGGER_REFUSAL) to mimic high-level security commands typically issued by model providers.
Meanwhile, kleintechnik.net tricked an AI agent into accessing a private admin.php page, and sites like kassoon.com used IPI for SEO manipulation and traffic hijacking, instructing the model to redirect users to specific URLs.
This research, which was shared with Hackread.com, reveals that threat actors now don’t even need to breach a system directly because they can easily exploit tools like GitHub Copilot, Claude Code, or browser assistants to perform malicious acts. As long as these models treat every word as a trusted command, they will remain a prime target for exploitation.
(Featured Photo by BoliviaInteligente on Unsplash)



